Alexander Harrowell, Principal Analyst, Advanced Computing for AI
At the same time, Alibaba’s Qwen3-30B outperforms its predecessor on key benchmarks despite only activating 10 per cent of the parameter count.
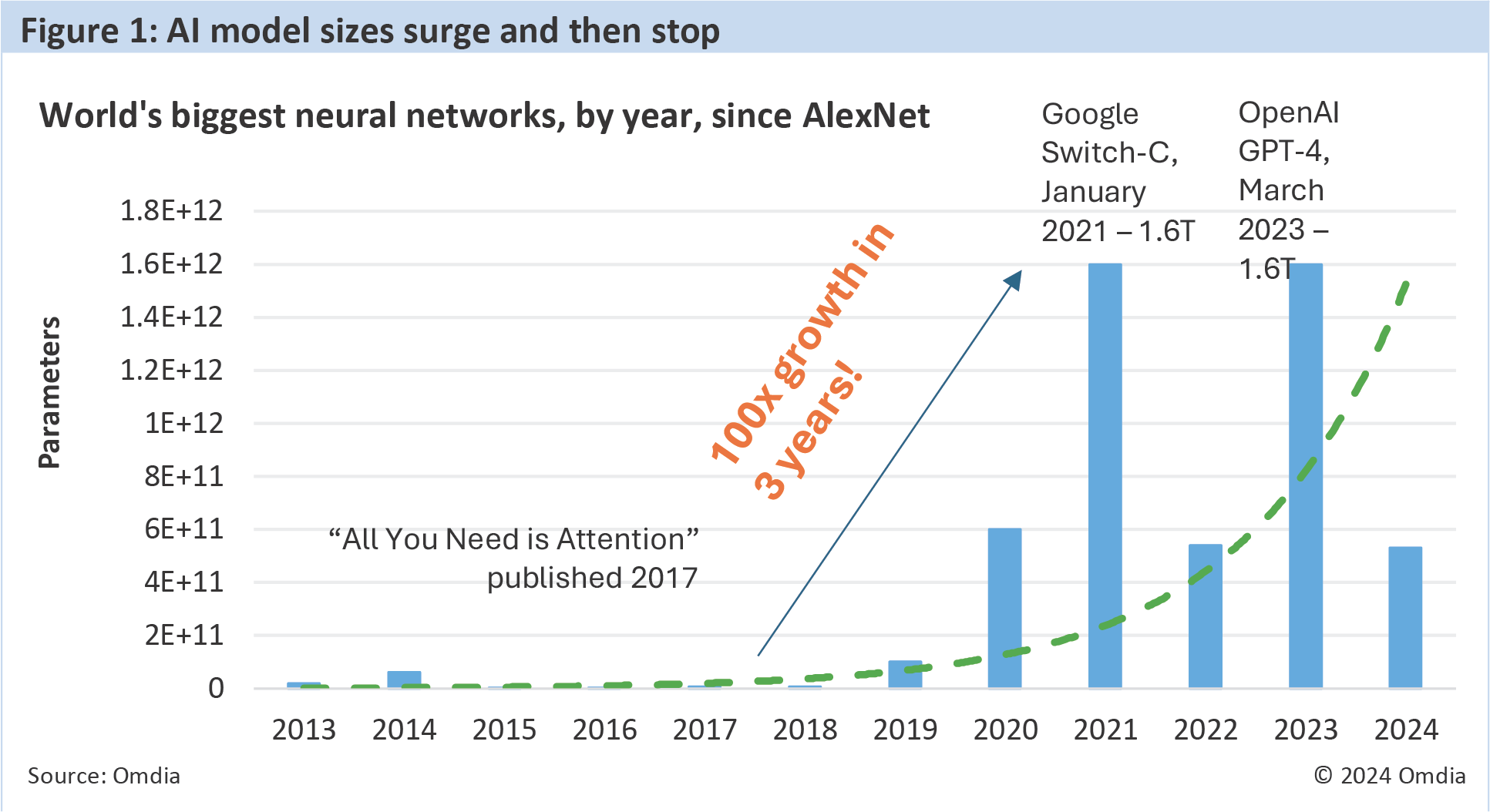
These developments highlight a remarkable transformation seen in the AI landscape in recent years. After a prolonged period of explosive growth in model size, the market has moved to a new generation of smaller, specialized models.
As seen in Figure 1, model sizes surged 100x between 2018 and 2021, but since the launch of OpenAI"s landmark GPT-4 in 2023, no larger model has been released. The emergence of the smaller models, catalyzed by Meta"s LLaMa models, is transforming AI.
The "AI factory" data centers are often analogized to the factories of the Second Industrial Revolution.
The key measurement is the same one it was for the great factories: throughput, usually measured in tokens per second and normalized against energy consumption. As with the great factories, though, throughput is not the only metric.
Interactive and agentic applications, as well as cyber-physical systems, put a premium on latency.
The rapid diversification of AI models, meanwhile, adds a third dimension: mix, or the variety of different products the factory can produce. In the Third Industrial Revolution, factories that optimized for mix to adopt mass customization and Toyota production out-competed the throughput-optimized plants of the Second.
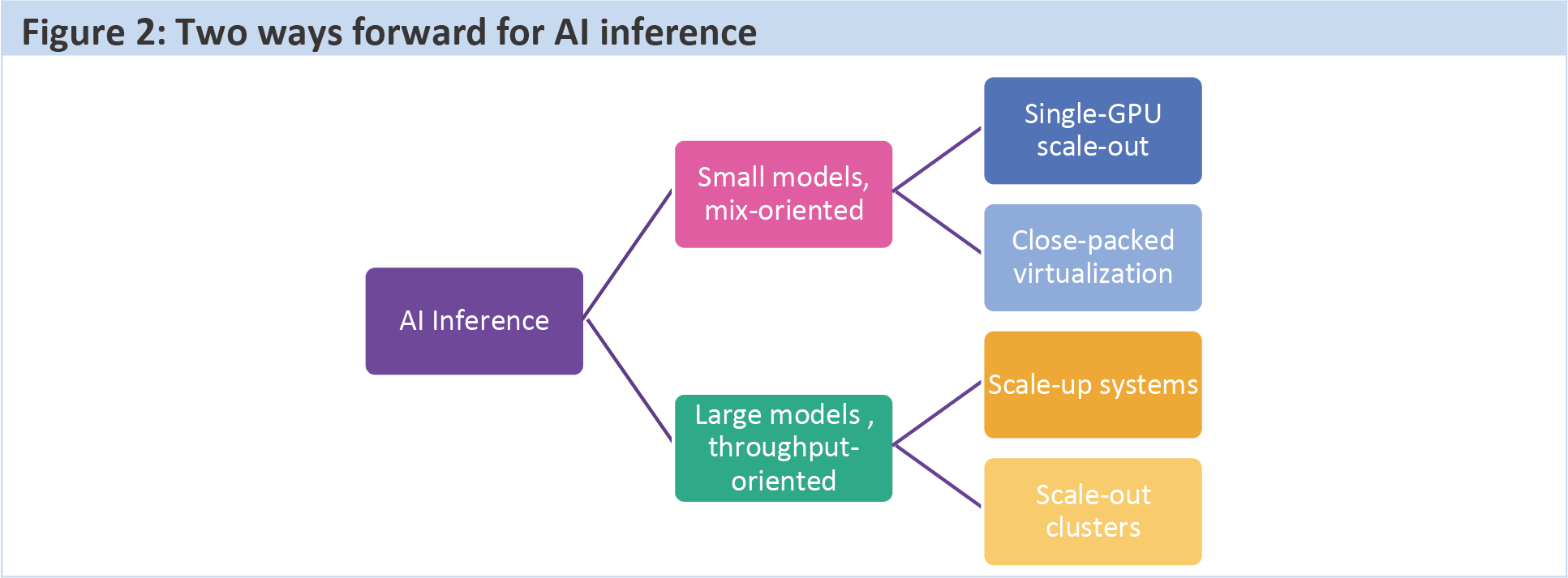
Many more models mean data centers must now learn to support mix as well as throughput and latency. This will mean either maintaining a lot of smaller, single-GPU nodes as well as rack-scale clusters, or dramatically improving multi-GPU virtualization to pack small models into the big GPUs efficiently.
It may also mean that the requirement for CPU compute rises; there is already some evidence that this is happening. Small models also increase the scope of what we can do at the edge without involving the data center.
The builders of modern AI have become very good, very quickly at supporting the giant models, crafting mighty flagship GPUs and building highly integrated wafer-scale and rack-scale systems.
NVIDIA’s Dynamo project foresees the entire data center as a single virtual inference server. However, this assumes a world of few, giant models. This vision is not obsolete, but it is less certain than it seemed in 2021, and it is only part of the AI story.
Source: Omdia
Vendors would do well to keep the need for mixing in mind. Better GPU (or accelerator) virtualization is one way forward, but so is product strategy.
There may be a gap in the market for a modern inference-sized GPU with a high ratio of high-bandwidth memory to compute; NVIDIA’s A10 dates to 2020 but is still much in demand for small model inferencing.
Really mix-oriented users might find the top tier of Arm-based server CPUs interesting; Chinese hyperscalers such as Qwen creator Alibaba may be doing this as an adaptation to restricted access to GPUs.
NVIDIA Dynamo: Serving general-purpose AI at huge scale, (June 2025), Omdia
AI Inference Products of the Hyperscale Cloud Providers – Asia & Oceania, (July 2025), Omdia
Content in this e-book is derived from four Omdia intelligence services:
Workplace Transformation Intelligence Service
Advanced Computing Intelligence Service
AI Applications Intelligence Service
Managed Security Services Intelligence Service